Byte Pair Encoder
Byte Pair Encoding(BPE)是一种数据压缩算法,后来被用于自然语言处理领域,尤其是在生成词嵌入和处理开放词汇问题时。BPE的核心思想是将频繁出现的字符对(byte pairs)合并为一个新的字符,从而减少文本中的总字符数。在自然语言处理中,BPE通常用于将文本分割成子词单元(subwords),这些子词单元可以在一定程度上减少数据稀疏性,提高模型的泛化能力。
minGPT 的 bpe 实现中的介绍:
它将任意的utf-8字符串转换为整数序列,其中每个整数表示常见字符的小块。
此实现基于openai的gpt2 encoder.py:
https://github.com/openai/gpt-2/blob/master/src/encoder.py,
BPE已经在许多自然语言处理任务中取得了成功,如机器翻译、语言模型和预训练语言模型(如BERT、GPT-2等)。
算法
BPE 的基本思想是将频繁出现的字符对(或者说是字节对)合并为一个单一的符号。这个过程会反复进行,直到达到预定的词汇表大小,或者没有可以合并的字符对为止。
Step1:文本分解
将文本分解为字符级别的 token
Step2:频率统计
统计所有 token 对的频率,并找出频率最高的 token 对。
Step3:生成新 token
将频率最高的 token 对合并为一个新的 token。
Step4:重复统计、生成
重复步骤2和3,直到达到预定的词汇表大小,或者没有可以合并的 token 对为止。
举例
例如,假设我们有一个句子 "aaabdaaabac",我们可以将其分解为字符级别的 token ["a", "a", "a", "b", "d", "a", "a", "a", "b", "a", "c"]。然后我们统计所有的 token 对的频率,发现 ("a", "a") 的频率最高,于是我们将其合并为一个新的 token "aa"。这样,我们就得到了新的 token 列表 ["aa", "ab", "d", "aa", "ab", "ac"]。我们可以继续这个过程,直到达到预定的词汇表大小,或者没有可以合并的 token 对为止。
在自然语言处理中,BPE的一个重要应用是用于构建词汇表。通过将文本分割为子词单元,可以有效地减少数据稀疏性,提高模型的泛化能力。此外,子词分割方法还可以帮助处理未知词汇(如拼写错误、罕见词等),因为这些词汇的子词可能已经在训练集中出现。
BPE 的一个重要优点是它可以有效地处理未知词和罕见词。因为即使一个词在训练数据中没有出现过,只要它的子词在训练数据中出现过,我们就可以用这些子词来表示这个词。这使得 BPE 在处理大规模和复杂的语言数据时,特别是在机器翻译等任务中,表现出了很好的效果。
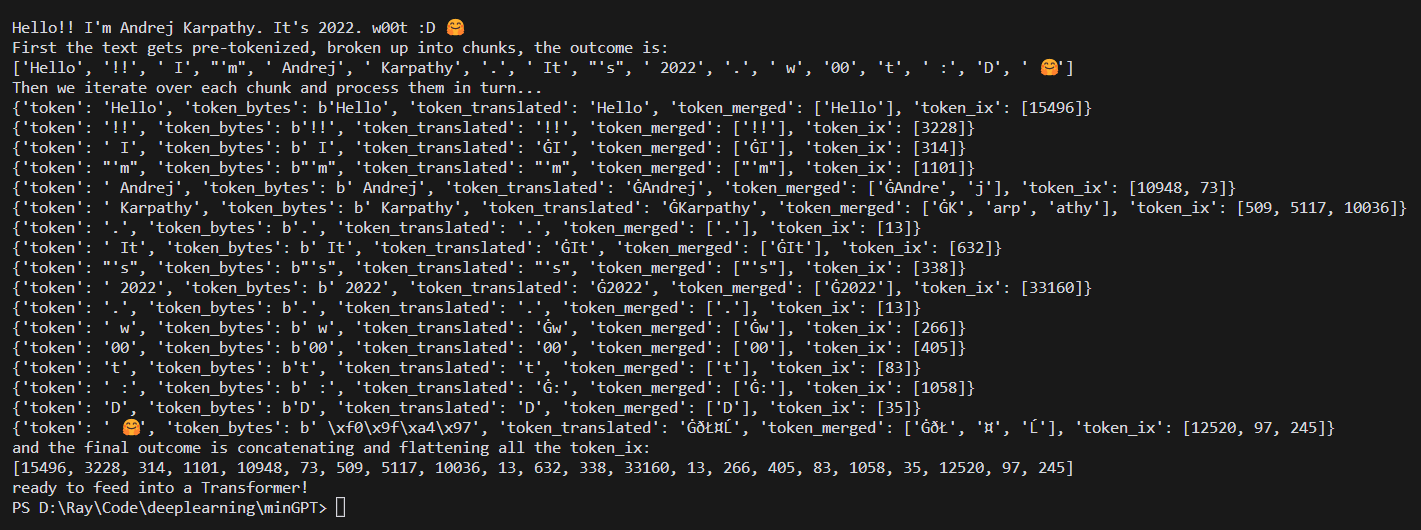
实例
minGPT 中 BPE 实现的运行效果:
改进算法
网络资源
- 理解NLP最重要的编码方式 — Byte Pair Encoding (BPE),这一篇就够了 - 知乎 (zhihu.com)
- 彻底搞懂BPE(Byte Pair Encode)原理(附代码实现)_bpe代码_无名草鸟的博客-CSDN博客
- 浅谈Byte-Level BPE - 知乎 (zhihu.com)
- BPE 算法原理及使用指南【深入浅出】 - 知乎 (zhihu.com)
- 字节对编码-Byte Pair Encoding - 知乎 (zhihu.com)
本文作者:Maeiee
本文链接:Byte Pair Encoder
版权声明:如无特别声明,本文即为原创文章,版权归 Maeiee 所有,未经允许不得转载!
喜欢我文章的朋友请随缘打赏,鼓励我创作更多更好的作品!
